一個專業的IDP系統至少需要具備如下兩方面的能力,才能夠滿足富格式文檔的智能化處理需求。
由于文檔本身多模態的特點,決定了IDP系統必須能夠綜合應用計算機視覺和自然語言處理等技術,包括圖像處理、OCR、表格識別、文檔解析、文本分析、文本理解等,對于文檔中的標題、段落、表格、圖表、印章、簽名等多模態信息進行識別、提取和進一步的理解和分析。
由于不同領域的文檔特征差異很大,為了在領域數據上達到業務可用的精度要求,IDP系統必須具備領域樣本高效學習能力,能夠生成優化后的模型,滿足業務場景應用需求,為實際業務創造價值。
多模態能力和領域學習能力等方面的要求,決定了通用IDP系統是一個復雜的綜合性軟件系統,對于技術架構和系統設計提出了很高的要求。架構上,IDP系統需要能夠兼容各種深度學習框架,并能夠對于各種預訓練大模型、多模態預置模型和用戶自訓練的領域模型實現有效的模型治理。并且,能夠以統一的模型能力層,向文檔應用層提供接口,滿足上層智能化應用的調用需求。如下圖,是一個常見的IDP系統模型技術棧。可以看出,LLMs僅僅是在自然語言文本這個模態上,作為預訓練基礎模型(如紅色高亮部分)。相比于文本領域的處理能力,IDP系統中更加核心的功能在于文檔圖像和多模態信息的綜合處理能力,包括OCR、表格識別、印章識別,以及文檔分類、信息檢索和文檔抽取等。

圖2 IDP模型技術棧
因此,對于IDP系統,大語言模型主要作用是幫助提升文檔文本的理解和生成能力,尚無法完全替代IDP模型技術棧。
利用大語言模型強大的文本理解能力,提升文檔中文本信息的分類能力,如段落和條款,進而提升文檔信息檢索和文檔分類的效果。
相比于BERT等大語言模型,GPT大模型具備生成式的特點,能夠更好滿足文檔知識實時問答的應用,幫助實現諸如“與你的文檔聊天”等應用功能。
大語言模型在文本信息抽取方面具備強大的能力,如從特定條款或段落中抽取實體、關系和事件,幫助提升文檔關鍵信息抽取能力。
利用大語言模型強大的理解能力,能夠提升文檔中不同條款、段落之間,以及與標準條款和段落的比對精度,改善文檔比對效果。大語言模型在幫助提升IDP文本處理能力的同時,也面臨諸多挑戰和風險,主要包括:
GPT-4具有最大32K Token輸入和25K Word輸入的要求,限制了對于長文檔的處理能力,如幾十上百頁的合同和報告文件。這就要求必須通過前置的信息檢索或段落抽取等預處理,提取出大篇幅文檔中的相關部分,再輸入大模型進行后續任務處理。
不同于BERT等大模型,GPT(Generative Pre-trained Tranformer)模型屬于生成式語言模型,對于模型輸出的信息無法進行精準溯源,即很多情況下無法準確獲得輸出內容在文檔中的具體位置,這就增加了輸出的風險性。在對于模型精準度要求高的場景下,如金融業務場景,往往極小概率的風險也會帶來巨大的損失。因此,就需要通過模型優化和后處理等方法進行有效規避,避免非法輸出問題。
上文提到,文檔的一大特征在于其領域信息的多樣性和差異性。通用大語言模型通常基于公開的互聯網語料訓練獲得,包括維基百科、新聞文章、社交媒體等,因此,缺乏對于領域知識的深度學習和理解。實際應用中,必須結合領域數據基于預訓練語言模型進行學習和調優,以達到實際業務場景的使用要求,這也是IDP系統必須具備高效學習能力的根本原因。
大模型通常具備較大的參數規模,如GPT-3.5有1750億參數,對于本地化和私有化部署場景下的算力成本具有很高的要求。因此,這些場景下,必須進行模型輕量化處理才能真正落地使用,如通過知識蒸餾和模型量化等技術。賽博結合大模型技術打造高效學習能力,提供IDP全新解決方案賽博智能學習平臺定位于一站式機器學習平臺,基于預置的多模態能力和高效的領域數據學習能力,支持對于圖片和文檔等非結構化數據的智能化處理。在預置多模態能力的基礎上,提供高效的領域數據學習能力,是賽博平臺智能文檔處理的核心優勢。如下圖,是關于賽博平臺智能文檔處理的核心能力介紹。

圖3 賽博平臺智能文檔處理核心能力
提供通用文檔圖像檢測、區域分割和矯正、文檔圖像質量檢測(模糊、反光、遮擋、拍屏、水印、復印、篡改、變形、切邊和距離遠等)、干擾和噪聲去除等預置能力。
提供通用和場景OCR功能。通用OCR支持對于常見的文檔圖像要素的識別,包括文本(打印、手寫、多語言)、表格、印章、勾選和簽名等。場景OCR功能支持超過50種場景文檔圖像的識別能力,涵蓋標準卡證、票據、表單和憑證。
提供通用的文檔處理能力,包括文檔格式轉換、協議解析、版面分析、文檔解析等,以及合同等場景文檔抽取能力。
提供基礎的自然語言處理功能,包括文本分類、信息抽取、通用問答、情感分析等。
如前節所述,文檔具有領域特征差異大的特點,主要表現在不同領域文檔之間在種類、版式、語料和表達方式等方面存在較大差異。因此,高效的領域文檔學習能力,是IDP系統必備的基本功能,這也是賽博平臺的核心功能之一。如下圖是關于賽博平臺高效學習能力的原理介紹。
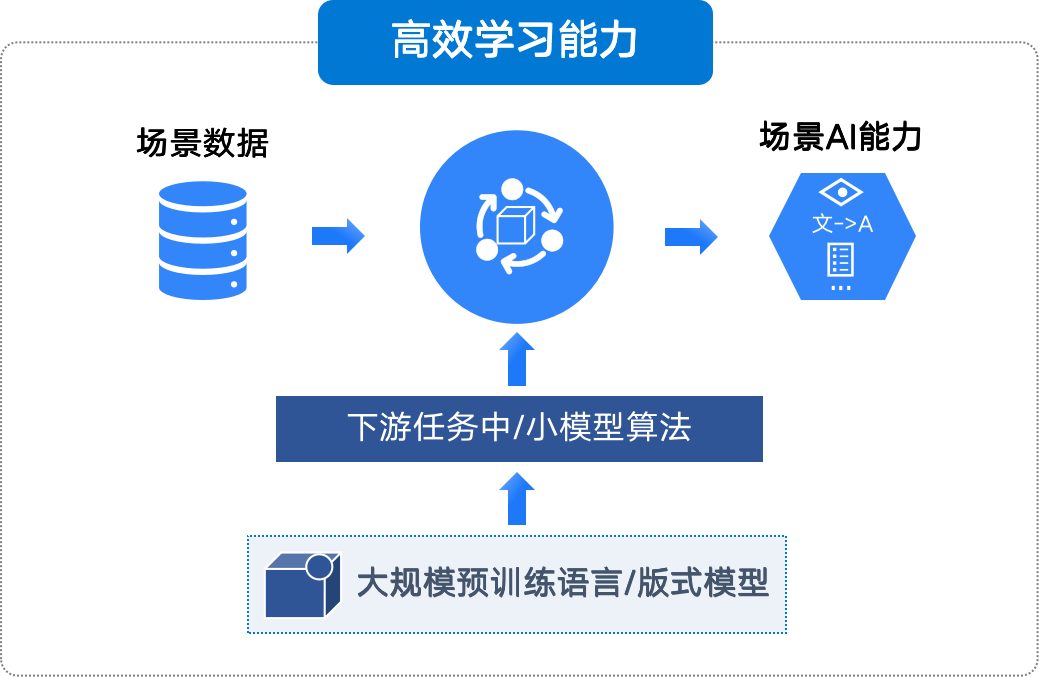
圖4 賽博學習能力
賽博平臺IDP學習能力以大規模語言模型和文檔版式預訓練模型為基礎,通過下游任務中/小模型算法設計,結合領域數據,高效生成場景模型,并通過一鍵式模型部署和API生成,輸出場景化AI能力,如文檔分類、信息檢索、文檔抽取、段落比對等。依托機器學習功能底座,賽博平臺能夠提供文檔數據集標注、模型訓練、模型部署和API應用等一體化操作功能,支持用戶通過可視化頁面,高效完成領域文檔數據的學習和模型能力的輸出與應用。另外,為了更好地滿足業務場景需求,實現與業務深度融合,賽博平臺支持模型輸出規則和API代碼補丁定制,能夠在線實現模型輸出格式轉換、字段拆分與合并、噪聲剔除以及其他高級后處理功能,有效解決模型輸出與業務需求之間“最后一公里”的問題。未來,易道博識將繼續立足于金融、能源、通信等行業,圍繞企業在日常業務運營、審核和監督管理、信息檢索和風險管控等場景下的數智化轉型需求,依托賽博智能學習平臺底座,在滿足客戶數據安全的前提下,通過高效學習能力,將大模型等前沿技術與客戶業務數據相結合,發揮巨大效能,通過與業務場景的深度融合,為業務賦能。






